Overview
A spanning tree is a sub-graph of an undirected connected graph, which includes all the vertices with a minimum possible number of edges. Suppose a complete graph has vertices; the total number of spanning trees equals . Furthermore, the edges may or may not have weights assigned to them. But if it has, some algorithms can be used to find the spanning tree whose total weight is the smallest. We call this a minimum-spanning tree.
A minimum spanning tree (MST) or minimum weight spanning tree is a subset of the edges of a connected, edge-weighted undirected graph that connects all the vertices together without any cycles, and with the minimum possible total edge weight. The following is an example.
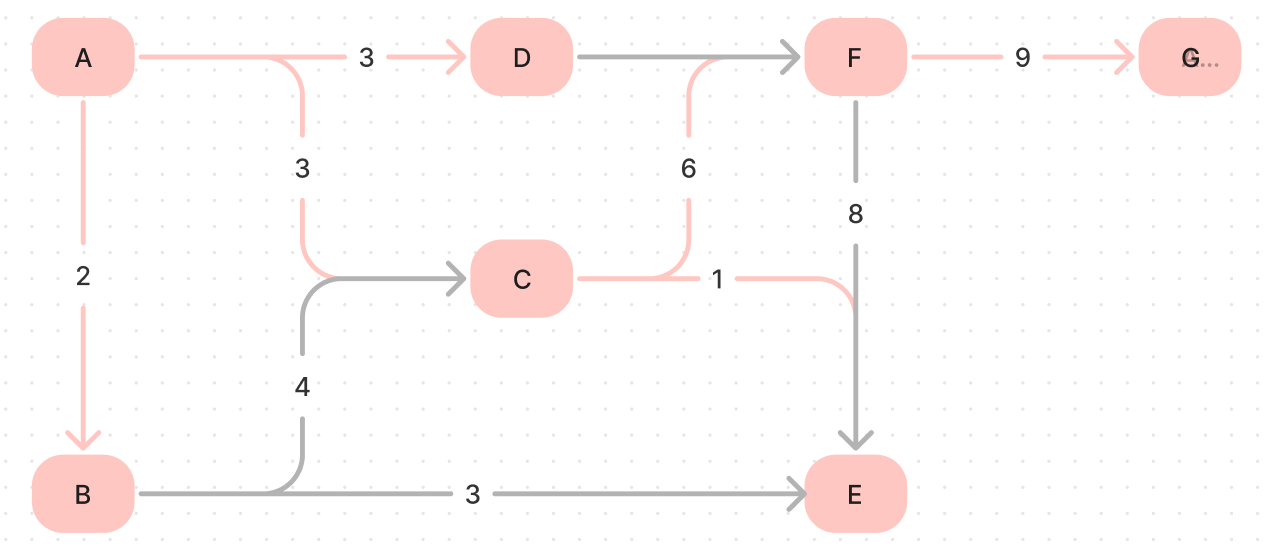
The red vertices and edges show one of the minimum spanning trees of the original graph. It’s essential to understand if we allow some edges in the graph have the same weight, the MST of this graph is most likely not unique.
This article will introduce a way to implement the weighted graph first. We implemented it when we introduced the fundamental knowledge, but to work with two algorithms we will mention later, we need to add some methods for the weighted graph class. Secondly, we will introduce two famous algorithms for finding the minimum spanning tree: Prim’s algorithm and Kruskal’s algorithm. The code of these two algorithms is based on the priority queue and the disjoint set. We will skip the first and introduce the second data structure’s details. The reason why we use additional data structure is to reduce the complexity of the code.
Weighted graph
Recalling the fundamental knowledge about the graph in Algorithm Connect! Re: Dive - Graph, we showed how to implement the weighted graph. This time we will use Kotlin’s excellent syntax to finish this work.
The first task is to define Edge class. The edge is a line to connect two vertices in a graph. Therefore, the best data structure to express this logic is Pair. The following is the code with comments.
// weight is an abstract concepts
class Edge<T>(start: T, end: T, val weight: Int) {
// pair represents a generic pair of two values
val connect: Pair<T, T> = start to end
// setup the getter for reducing code complexity
val start get() = connect.first
val end get() = connect.second
}Based on the definition of Edge class, we can implement GraphWeighted class. Some fundamental methods will be implemented in this class, such as addVertices, addEdge, removeVertex, removeEdge. Additionally, for ease of use in this class, we also implement some helper functions to allow the client access to internal fields. The following is the code with comments.
class GraphWeighted<T> (private val isDirected: Boolean) {
// adj stores each vertices and edges connected to them
private val adj: MutableMap<T, MutableList<Edge<T>>> = mutableMapOf()
// support adding mutiple vertices in once calling
fun addVertices(vararg vertices: T) {
vertices.forEach {
if (!adj.contains(it)) {
// new vertie doesn't have related edges
adj[it] = mutableListOf()
}
}
}
// add edge for any two vertices
fun addEdge(a: T, b: T, weight: Int) {
// add missing vertices
addVertices(a, b)
adj[a]?.add(Edge(a, b, weight))
// edges of undirected graph is bidirected
if (!isDirected) {
adj[b]?.add(Edge(b, a, weight))
}
}
// remove a vertex from graph
fun removeVertex(v: T) {
if (isDirected) {
// remove all edges pointed to this vertex
// edges start from this vertex will be removed when we remove vertex
adj.keys.forEach { key ->
adj[key]?.remove(
adj[key]?.find { it.end == v }
)
}
} else {
// remove all edges releated to this vertex
// therefore we need to traverse the edges list
adj[v]?.forEach { key ->
adj[key.end]?.remove(
adj[key.end]?.find { it.end == v }
)
}
}
// after cleanning up edges, remove this vertex
adj.remove(v)
}
fun removeEdge(a: T, b: T) {
// check if edges are existed in the graph
// error handling is not major topic thus using simplest one
val v1 = adj[a] ?: throw Error("Graph doesn't have $a")
val v2 = adj[b] ?: throw Error("Graph doesn't have $b")
v1.remove(v1.find { it.end == b })
// same logic with addEdge function
if (!isDirected) {
v2.remove(v2.find { it.end == a })
}
}
}Furthermore, some functions will be added to GraphWeighted class to make it work with other code efficiently. The following code is an example.
class GraphWeighted<T> (private val isDirected: Boolean) {
// ...
// check if vertex v exists in the graph
fun hasVertex(v: T): Boolean = adj.containsKey(v)
// check if there is a edge exists between vertex a & b
fun hasEdge(a: T, b: T): Boolean {
return if (isDirected) {
adj[a]?.find { it.end == b } != null
} else {
adj[a]?.find { it.end == b } != null &&
adj[b]?.find { it.end == a } != null
}
}
// some helper functions to expose internal fields
fun vertices(): MutableList<T> = adj.keys.toMutableList()
fun edges(v: T): MutableList<Edge<T>>? = adj[v]
fun adjList(): MutableMap<T, MutableList<Edge<T>>> = adj
}Again, although we used Kotlin to implement the GraphWeighted class, you can still choose other languages or ways to do it. The crux of this is to store weight in edges. Weight can be an abstract concept, not a concrete weight or distance.
Based on the understanding of the weighted graph, we can introduce two algorithms for finding minimum spanning trees.
Prim’s algorithm
Before talking about the prim’s algorithm, we want to emphasize the definition of the minimum spanning tree. The minimum spanning tree is a subset of the original graph’s edges which satisfies the following:
- Includes all vertices
- All vertices are connected
- Without cycle
- Has the minimum sun of weight
Prim’s algorithm takes vertices as objects of observation. The idea is that if the result is a minimum spanning tree, each step in generating it chooses a minimum edge. Therefore, we can choose one vertex every time. Suppose the set of chosen vertices is set a, and the remaining vertices are set b. We call the edges between set A and set B cuts. The algorithm chooses one edge from cuts at each step until all vertices have been selected.
If you prefer watching videos to understand the mechanism of Prim’s algorithm, this video will be the best choice.
In this algorithm, we use two external data structures. Although we can implement all the logic completely ourselves, we don’t think it’s a good practice. First, implementing all details makes the skeleton of the algorithm becomes ambiguous. Second, it equals breaking the external data structure and writing it into the algorithm. Because of this, we use a mutable set to record visited vertices and a priority queue to store candidate edges. Notice that we check if the start and end vertex on edge is visited before adding it to the result. Thus there is no need to rebuild priority after adding a new vertex. The following is the code.
fun <T> primMST(graph: GraphWeighted<T>): MutableList<Edge<T>> {
// the minimum spanning tree
val mst = mutableListOf<Edge<T>>()
// record the visited vertices to prevent infinity cycle
val visited = mutableSetOf<T>()
// store ordered candidate edges
val queue = PriorityQueue<Edge<T>> { e1, e2 -> e1.weight - e2.weight }
// initialize the data
val firstVertex = graph.vertices()[0]
visited.add(firstVertex)
graph.edges(firstVertex)?.let { queue.addAll(it) }
while (queue.isNotEmpty()) {
// chose the minimum edge from queue
val edge = queue.poll()
// if two vertices are visited, skip current process and move on to the next edge
// if one vertex is visited, current process connects two adjacent area
// if no vertex is visted, current process creates a new area
if (visited.contains(edge.start) && visited.contains(edge.end)) continue
// add a edge to result
mst.add(edge)
// add candidate edges
if (!visited.contains(edge.start)) {
visited.add(edge.start)
graph.edges(edge.start)?.let { queue.addAll(it) }
}
if (!visited.contains(edge.end)) {
visited.add(edge.end)
graph.edges(edge.end)?.let { queue.addAll(it) }
}
}
}Kruskal’s algorithm
Compared with Prim’s algorithm, this one focus on the edges of the whole graph instead of a specific vertex. The idea is to pick an edge orderly at a time and put it into the minimum spanning tree’s edge set. If the final result is a minimum spanning tree, the edge picked in this process will be the minimum one at that moment. But the issue with this logic is that the edges picked orderly may generate a cycle. The solution is only to pick the edges, which are cuts. Here is the best video explaining the cut theory for anyone unfamiliar with this term.
Summarizing the discussion, the idea behind this algorithm is to select edges orderly from the set of cuts. Or in other words, choose edges and check if it’s a cut edge before adding it to the result. To satisfy this requirement, we need to implement a data structure called disjoint set first. And then, we will use this data structure to implement Kruskal’s algorithm.
Disjoint set
The disjoint set is a data structure distinguishing the collections to which different elements belong. You can imagine the Set in mathematics.
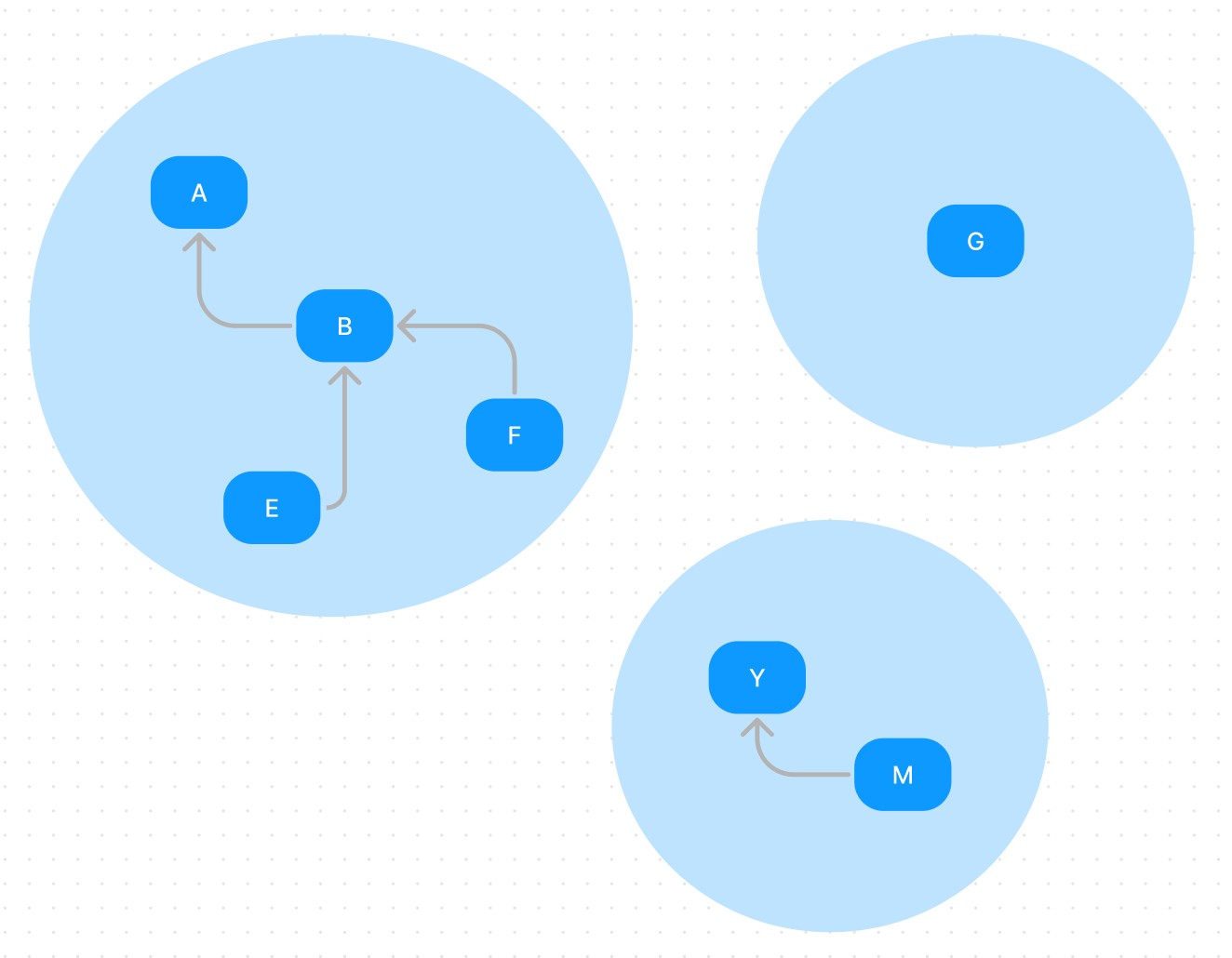
As shown in the illustration, this data structure can maintain multiple sets and check if an element belongs to any set or add a new element to any set. We use a hash map to implement this data structure cause we want to support any type. You can use any other way to finish this work, like using an array if you only want to support number type.
Our solution considers the set as an N-fork tree and uses a hash map to store the relationships between elements. To add a new element, we can link it to any leaf element of that tree. To check if an element belongs to any set , we can traverse the hash map to find the parent node. Two elements only belong to the same set if their root node is the same. We can use the following type to describe the hash map.
<T : type of current element, T : type of parent element>The following is the code. It’s worth highlighting that we only implemented the basic function of this data structure. If you want to implement a more general data structure, you need to add more methods for it by yourself.
class DisjointSet<T> {
private val parent = mutableMapOf<T, T>()
// find the root node of given element
private fun find(element: T): T{
var root = element
// follow the path from leaf to root
while (parent.contains(root) && root != parent[root]) {
root = parent[root]!!
}
return root
}
fun union(e1: T, e2: T) {
// find the root
val r1 = find(e1)
val r2 = find(e2)
// if e1 and e2 belong to different sets
// link them together
if (r1 != r2) {
parent[r1] = r2
}
}
fun isSameSet(e1: T, e2: T): Boolean = find(e1) == find(e2)
}You may notice that we link two sets via the root node in the union procedure. It’s accepted that they link them on a leaf node. This involves the trade-off between the union and the find procedure, which function should carry on more time complexity.
Implementation
Based on the disjoint set above, it’s easy to implement Kruskal’s algorithm for searching the minimum spanning tree. We have discussed the mechanism behind this algorithm at the beginning of this section. You can watch this video to learn more details about this algorithm. Here is the code:
fun <T> kruskalMST(graph: GraphWeighted<T>): MutableList<Edge<T>> {
// the minimum spanning tree
val mst = mutableListOf<Edge<T>>()
// candidate edges
val edges = graph.adjList().flatMap { it.value }.sortedBy { it.weight }
val ds = DisjointSet<T>()
for (edge in edges) {
// only use the cut edges
// in other words, vertices on edge belong to different area
if (!ds.isSameSet(edge.start, edge.end)) {
mst.add(edge)
// record the new relationship
ds.union(edge.start, edge.end)
}
}
return mst
}